
How to use Apache Flink for High-Volume Stream Processing
The article provides in-depth insights into quantifying workload requirements, optimizing cluster resources, managing distributed state, and efficiently scaling source and sink connectors. It serves as a guide for implementing Apache Flink in production environments where terabytes of data are processed daily, ensuring effective scaling and performance optimization.


Real-time data processing platforms, such as Apache Flink, are becoming indispensable for businesses aiming to harness the power of data. Flink's distributed architecture, renowned for its exceptional throughput and minimal latency, positions it as an ideal solution for mission-critical, large-scale data workloads. Nevertheless, despite its inherent scalability, production environments processing terabytes of data daily necessitate careful consideration of operational complexities, data distribution strategies, and fault tolerance mechanisms.
To accommodate the massive scale of modern data streams, architects must meticulously examine Flink pipelines from ingestion to consumption. By expertly employing diverse orchestration strategies, they can seamlessly scale streaming applications, powering critical business metrics, real-time dashboards, and sophisticated data science models that process billions of events daily.
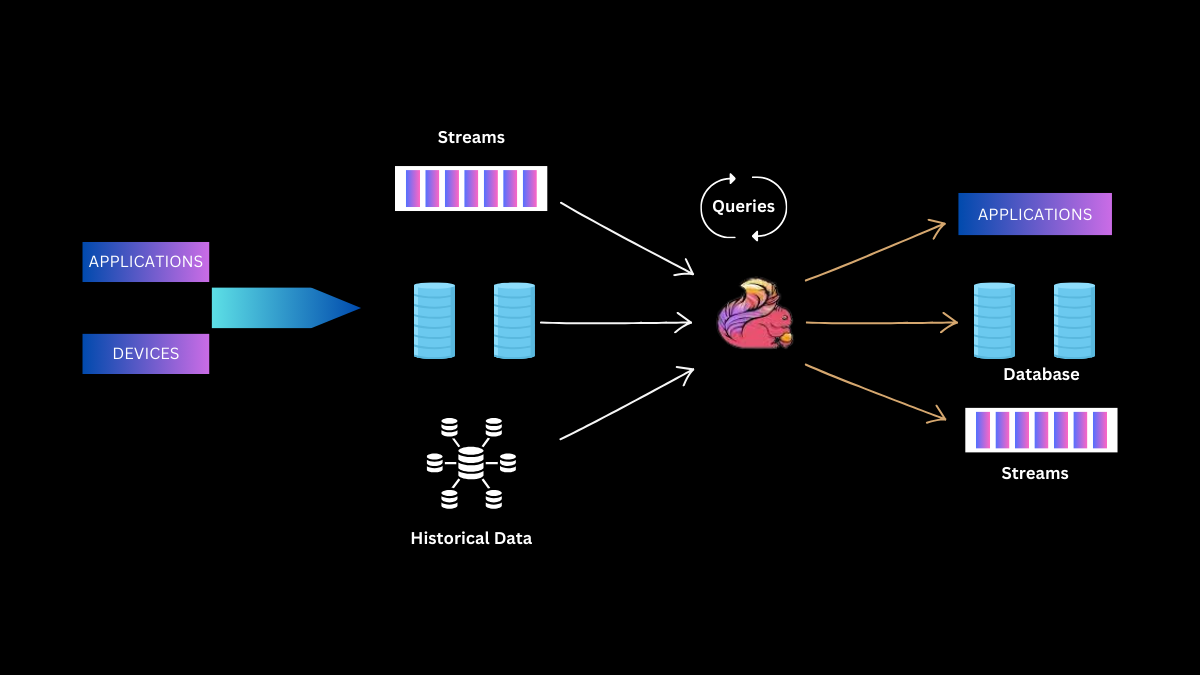
Quantifying Workload Requirements
Initiate the process by meticulously identifying comprehensive workload requirements and constraints, encompassing both functional and non-functional aspects. Key attributes to consider include:
- Data volume and ingress patterns - bursts, spikes etc.
- Data accumulation over window for analysis. Example: > 1 TB/day
- Processing needs - enrichment, cleansing, transformations
- Analytics latency thresholds < 500 ms
- Uptime SLAs - 99.99%
- Output velocity for downstream consumption
- Cost budgets
Implement robust instrumentation to capture granular metrics on throughput, data shuffle sizes, and function-level processing times. Conduct in-depth analysis of pipeline DAGs to pinpoint potential scaling bottlenecks. This data-driven approach enables precise resource allocation for optimal performance.
For example, handling daily data loads surpassing 1 terabyte and demanding sub-second response times necessitates provisioning for peak ingestion rates exceeding 40,000 events per second. To ensure data durability and system resilience, checkpointing intervals must be carefully calibrated. Data-driven modeling aids in sizing infrastructure and fine-tuning Flink configurations.
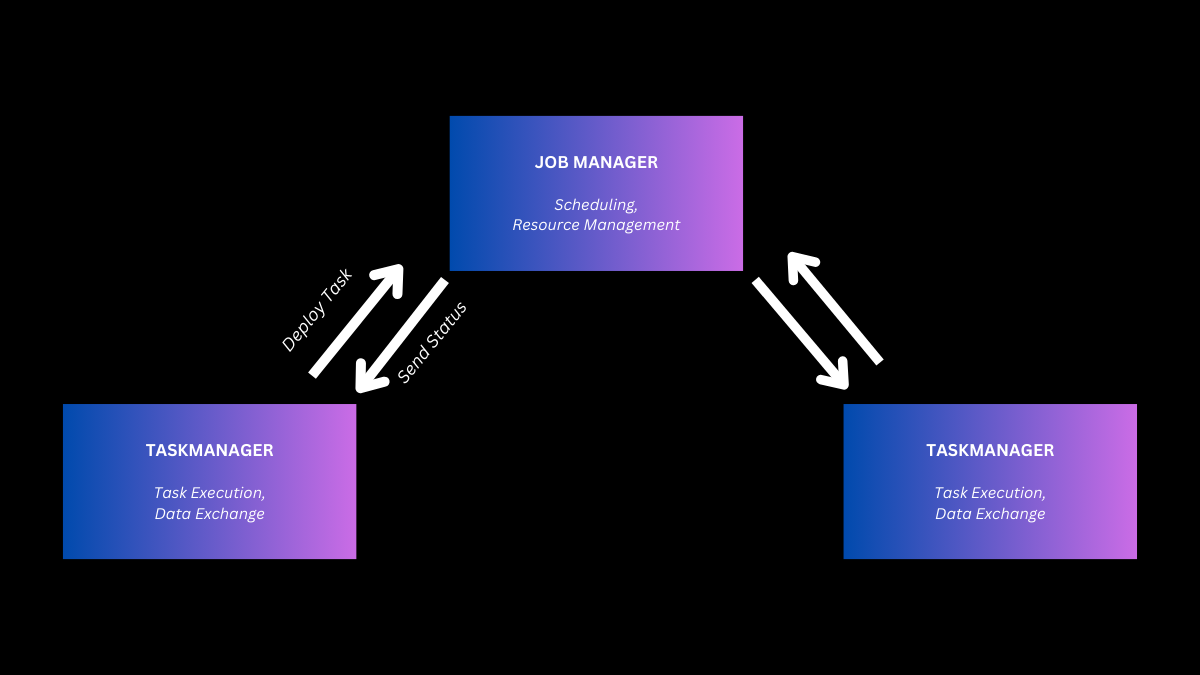
Scaling Cluster Resources
Accurately sizing TaskManagers is crucial for efficient resource utilization. By analyzing workload data, you can model the optimal configuration of CPUs, memory, and network I/O. Underprovisioning memory leads to excessive disk I/O, while overprovisioning CPUs can result in wasted resources. To strike the right balance, consider factors like slot-to-task ratios. For instance, a 16-slot, 64GB TaskManager can efficiently handle approximately four parallel tasks per CPU.
Ensure optimal JobManager sizing to harmonize with worker node capacity. An undersized JobManager can hinder the coordination of large clusters, regardless of available slots. Implement robust high-availability configurations with standby masters. Rigorously monitor cluster load during failover events. If performance degradation is observed, promptly adjust JobManager resources. Design your cluster architecture to accommodate peak data rates and seamlessly adapt to fluctuating workloads through infrastructure elasticity and auto-scaling mechanisms.
Tuning Parallelism & Distribution Factors
Optimize Flink job performance by adjusting parallelism levels to target identified bottlenecks.
- Operator Parallelism: For high compute UDFs with low output volume like ML scoring.
- Transport Parallelism: For huge shuffle data exchanges like window aggregates.
- Task Slots: Balance slot-to-core ratio across desired parallelism.
- Maximum System Parallelism: Set 20-50% above expected peak load.
By fine-tuning these parameters, pipeline capacity can be strategically allocated across cluster resources. This delicate balancing act optimizes resource utilization, even in high-scale environments.
To minimize recovery costs, fine-tune delivery guarantee timeouts. Furthermore, consider shedding load during peak periods by temporarily discarding non-critical data streams. For instance, during high traffic, reduce the accuracy of aggregated metrics to 98% to alleviate system strain.
Managing Distributed State at Scale
Flink offers a versatile suite of state backends, each tailored to specific performance and scalability requirements.
- MemoryStateBackend: Low latency but loses state onfailures and limited capacity.
- FsStateBackend: Writes state checkpoints to distributed filesystems like S3/HDFS to transparently scale capacity. Limited only by underlying filesystem.
- RocksDBStateBackend: Incremental key-value state store on TaskManager local storage. High performance read/writes than remote storage options. Local storage limits aggregate state capacity.
Select a backend infrastructure that optimizes data access and storage efficiency.
- Keyed State: RocksDB's indexed access well-suited for sharded key-partitioned state.
- Large Read-Only Broadcast State: FsStateBackend avoids replication overheads.
- Small Operator State: Memory backend minimizes serialization costs.
RocksDB excels in handling incremental state changes. However, to mitigate unbounded growth in continuous streaming scenarios, TTL-based expiration is essential. Compact state after window closure further optimizes read performance by reducing amplification.
Distribute state across multiple nodes to maximize parallel processing. Design a flexible state schema that supports horizontal scaling. Avoid complex state derivations within user-defined functions (UDFs) that hinder sharding. Allocate ample read and write resources to TaskManagers for efficient state operations.
Rebalancing Work Distribution at Runtime
Flink's dynamic rebalancing ensures optimal performance by automatically adjusting to uneven data distribution or outages. This process involves suspending upstream tasks, redistributing state, rerouting data flow, and resuming operations. By leveraging API or configuration flags, users can proactively trigger rebalancing to maintain balanced workloads and prevent performance degradation.
An alternative strategy involves workload balancing, where idle TaskManagers proactively claim excess tasks from overburdened nodes. This dynamic approach enhances resource efficiency without necessitating complete pipeline reboots.
Dynamically optimize infrastructure to adapt to fluctuating workloads through integrated repartitioning, autoscaling, monitoring, and orchestration.
Scaling Source, Sink & Externals
Flink operates as a processing engine, not a data ingestion or storage solution. To construct a comprehensive streaming pipeline, you'll need to integrate scalable source connectors for data extraction from diverse sources like streaming buses, files, or databases, and sink connectors for delivering processed data to storage systems. Common challenges in this setup include:
- Underprovisioned message queues saturating ability to ingest peak traffic.
- Few Kafka partitions throttling maximum read parallelism.
- Unsharded external databases/object stores becoming write bottlenecks.
Design and implement robust stream processing architectures to meet stringent concurrency, throughput, and availability SLAs. Leverage scalable NoSQL databases like MongoDB and Cassandra, as well as distributed streaming platforms like Kafka, to handle increasing data volumes efficiently. Optimize ancillary services such as Zookeeper and Schema Registry to prevent performance bottlenecks. Monitor critical metrics across the entire stream processing pipeline, including the Flink cluster, to ensure optimal system health.
Conclusion
Flink's inherent scalability can be harnessed to its full potential by adopting a holistic systems approach that considers data characteristics, computation patterns, and fault tolerance mechanisms. Distributing configurations across state storage, partitioning, batching, parallelism, and dynamic work rebalancing enables the creation of resilient, high-throughput stream processing pipelines. By leveraging workload analytics, organizations can optimize their Flink clusters for maximum scalability and efficiency.




No Hype. Just Systems That Deliver Real Outcomes at Scale.


A1004, Amar Business Zone, Baner, Pune, Maharashtra – 411045





