
How to Integrate Dbt and GreatExpectations
This blog post provides a step-by-step guide to integrating Dbt (Data Build Tool) and Great Expectations for enhancing data quality with E-commerce analytics as an example. It covers the entire process from setting up a project, transforming raw data into analytics-ready tables, to implementing data quality tests using a sample e-commerce dataset in Snowflake.


Data quality is crucial for making good data-driven decisions. As data volumes grow exponentially, automating data testing and documentation is key to maintaining high quality data in analytics databases. Dbt (Data Build Tool) and Great Expectations are two popular open-source frameworks that help tackle different aspects of managing analytics engineering pipelines.
In this post, we will walk through an end-to-end example of integrating Dbt and Great Expectations using an e-commerce dataset. We will load sample e-commerce order data into a Snowflake data warehouse. Dbt will help us transform the raw data into analytics-ready tables and views. Great Expectations will then help create data quality test suites validate the analytics dbt models.
Prerequisites to integrate Dbt and GreatExpectations
Before we begin, let's outline the key items we need:
- Access to a Snowflake account where the raw e-commerce data is loaded
- Create a database called ECOMM_ANALYTICS
- Dbt installed and configured to connect to Snowflake
- Great Expectations installed and connected to Snowflake
- Git/Github repository to manage Dbt and Great Expectations config as code
- Basic understanding of SQL, dbt, and Great Expectations
Sample E-Commerce Data Model
Our raw sample e-commerce data has information on customer orders, products, payments and order reviews stored in Snowflake stages.
Here is a snippet of what the raw orders data looks like:
And the products data:
We want to transform this raw data into an analytics dataset with clean, derived metrics like order revenue, product margins etc.
Here is what our target analytics data model looks like:
- stg_orders - staged orders data
- stg_products - staged products data
- stg_payments - staged payments data
- stg_reviews - staged reviews data
- fct_orders - derived metrics like order revenue, profit
- dim_customers - clean customer dimension
- dim_products - clean product dimension
This end-to-end pipeline is depicted below:
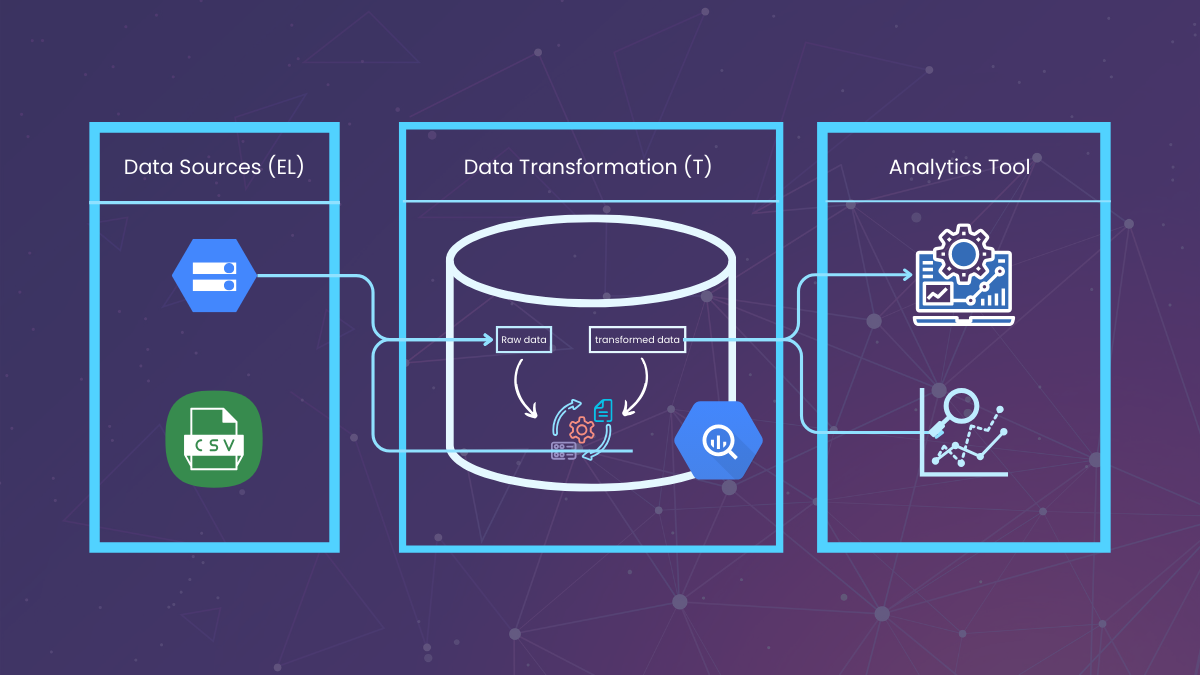
How to setup DBT project
We first setup a dbt project to build the transformations and generate the analytics dataset.
Initialize a dbt project ecomm_dbt and configure the connection to the Snowflake database ECOMM_ANALYTICS
Define the source and target schemas in the schema.yml file:
Build the dbt SQL models to transform raw data:
Run tests on dbt project:
- dbt compile to catch SQL errors
- Sample test suite:
Great Expectations Integration
Next, we setup Great Expectations to define data quality expectations and validate the analytics dataset.
- Initialize Great Expectations and connect it to the Snowflake database
Create a datasource pointing to the ECOMM_ANALYTICS database
Ingest metadata from dbt catalog:
Auto-generate expectations for dim_customers
Add custom expectations for metrics:
fct_orders.sql
Execute validation for customer 360 expectation suite:
Next Steps
Here are some ways we can build on this ETL monitoring framework:
- Schedule batched workflow for daily validation runs
- Set Data Docs to publish data quality results and metrics
- Expand test coverage for more edge cases
- Enable consumers to view data quality issues and fixes
Conclusion
In this post, we walked through a detailed example of integrating dbt and Great Expectations for an e-commerce pipeline using code snippets. Defining rigorous data quality tests is key to identifying issues early and maintaining high quality datasets.
Hopefully this gives you a blueprint to implementing automated data testing and documentation for your own data transformation pipelines!




No Hype. Just Systems That Deliver Real Outcomes at Scale.



A1004, Amar Business Zone, Baner, Pune, Maharashtra – 411045





