
How to build a RAG Using Langchain, Ollama, and Streamlit
In this blog, we guide you through the process of creating RAG that you can run locally on your machine. This journey will not only deepen your understanding of how cutting-edge language works but also equip you with the skills to implement them in your own projects.


Prerequisites: What You Need to Know
Before diving into the technicalities, let's outline the prerequisites. A foundational knowledge of Python is essential, as it is the primary language we'll be using. Familiarity with basic concepts in machine learning and NLP will help you grasp the concepts more easily. Additionally, having a general understanding of what Langchain, Ollama, and Streamlit are and how they function in the realm of AI and NLP will be beneficial. Don't worry if you're not an expert in these tools yet – this tutorial is designed to walk you through each step with clarity and detail.
Why Langchain, Ollama, and Streamlit?
Langchain, a powerful tool for language AI applications, will serve as our backbone, offering robust functionalities for integrating language and retrieval systems. Ollama, on the other hand, plays a crucial role in the RAG architecture, providing an efficient and scalable solution for information retrieval, which is fundamental to the RAG 's ability to pull in external knowledge. Streamlit, with its ease of use and flexibility, will be our choice for building a user-friendly interface, allowing you to interact with your RAG seamlessly. Join us on this exciting journey to unlock the potential of RAG. By the end of this tutorial, you'll not only have a deeper understanding of these advanced NLP technologies but also a fully functional RAG running on your local machine, ready to tackle a wide array of language processing tasks. Let's embark on this journey of discovery and innovation together!
Setting Up the Environment for Your RAG
Creating a robust and efficient environment is the bedrock of any successful software project, especially when dealing with advanced technologies like RAG. This section is dedicated to guiding you through the process of setting up an optimal development environment for building your Retrieval-Augmented Generation (RAG) using Langchain, Ollama, and Streamlit.
Python Installation: The Foundation of Our Project
Why Python? Python stands as the lingua franca of the machine learning world, known for its simplicity, readability, and vast ecosystem of libraries. Ensure you have Python installed on your system; this tutorial assumes a working knowledge of Python 3.6 or higher.
Installation Guide: If Python is not already installed, visit python.org for the latest version. Choose the installer appropriate for your operating system and follow the on-screen instructions.
Setting Up a Python Virtual Environment: Isolating Our Project
The Importance of Virtual Environments: Using a virtual environment allows us to manage dependencies for our project without affecting the global Python setup. It's a best practice that keeps our project clean and reduces the risk of version conflicts.
Creating a Virtual Environment: In your terminal or command prompt, navigate to your project directory and run python -m venv venv. This command creates a new virtual environment named venv in your project folder.
Activating the Environment: Before installing any packages, activate the virtual environment. On Windows, use venv\Scripts\activate, and on Unix or MacOS, use source venv/bin/activate. You should see the environment name in your console, indicating that it’s active.
Dependency Management: Installing the Necessary Libraries
Langchain and Ollama: These are the core libraries for our RAG. Langchain facilitates the integration of language with retrieval systems, while Ollama offers efficient retrieval capabilities.
Streamlit for UI: Streamlit will enable us to build a user interface for our effortlessly. It's known for its ease of use and rapid prototyping capabilities.
Installation Commands: Within the activated virtual environment, run the following commands:
- pip install langchain: Installs Langchain, our primary library for building the RAG .
- pip install ollama: Installs Ollama, which will handle the retrieval part of our RAG .
- pip install streamlit: Installs Streamlit, which we'll use to create a web interface for interacting with the .
Verifying the Setup: Ensuring Everything Is in Place
Check Versions: Use commands like python --version, pip list, and streamlit --version to verify that the correct versions of Python, Langchain, Ollama, and Streamlit are installed.
Test Run: Try running a basic Streamlit application or a simple script using Langchain to ensure that the installation is functional.
Preparing for Development: A Ready Environment
- Code Editor: Ensure you have a code editor or IDE (like VS Code, PyCharm, etc.) installed for a smooth development experience.
- Version Control: Consider initializing a Git repository in your project directory to manage version control efficiently.
With these steps completed, your environment is primed and ready. This foundation sets the stage for a seamless and productive development experience as we delve into the intricacies of building a Retrieval-Augmented Generation . Let's proceed with confidence, knowing our tools and environment are fully prepared to handle the exciting challenges ahead.
Introduction to Langchain: Unlocking Advanced Language AI Capabilities
As we venture into the realms of advanced language AI, Langchain emerges as a pivotal tool in our toolkit. Understanding Langchain is crucial for anyone aspiring to build sophisticated language , especially when integrating them with retrieval systems, like in the case of our Retrieval-Augmented Generation (RAG) .
What is Langchain?
Langchain: The Convergence of Language and Chain - Langchain is not just a library; it's a paradigm shift in how we approach language AI. Developed with the intention of chaining together different components of language AI systems, Langchain serves as a versatile and powerful framework. It facilitates seamless integration of large language with other elements, such as retrieval systems and databases, making it the perfect candidate for building RAG.
The Core Philosophy of Langchain
Modular Design: Langchain's architecture is inherently modular, allowing for plug-and-play functionality with various components. This modular approach empowers developers to experiment with different configurations and tailor solutions that best fit their specific requirements.
Scalability: Designed with scalability in mind, Langchain enables the handling of complex tasks and larger datasets without compromising performance, making it ideal for enterprise-level applications.
Community-Driven Development: Being open-source, Langchain benefits from the collective wisdom of the developer community, ensuring continuous improvement and adaptation to the evolving needs of the language AI domain.
Installation and Setup
Effortless Installation: Getting started with Langchain is straightforward. Once your Python environment is ready, installing Langchain is as simple as executing pip install langchain in your terminal or command prompt. This single command equips you with a robust toolkit to build advanced language AI applications.
Basic Usage of Langchain
A Sneak Peek into Langchain's Capabilities: To give you a taste of what Langchain is capable of, let's look at a simple example. Imagine creating a system that integrates a language with a retrieval system to answer complex queries. With Langchain, you can set up this integration in just a few lines of code, illustrating the library's power and ease of use.
Hands-On Example: In our tutorial, we will delve deeper, providing hands-on examples and detailed explanations. You'll learn how to use Langchain to fetch data from external sources, process it through a language , and generate insightful responses – the core of our RAG .
Why Langchain for RAG?
The Ideal Match for RAG: Langchain’s ability to integrate retrieval systems with generative makes it an ideal choice for building RAG. Its flexible and efficient design allows for the customization and fine-tuning necessary to achieve high-quality, contextually aware responses in our RAG application.
In conclusion, Langchain is not just a tool but a gateway to the future of language AI. Its versatility, scalability, and community-driven nature make it an indispensable asset for our project. As we progress through this tutorial, you'll witness firsthand how Langchain can transform your approach to building advanced language AI solutions. Let's embark on this journey with Langchain, unlocking new possibilities and pushing the boundaries of what's achievable in the world of language AI.
Introduction to Ollama: Revolutionizing Information Retrieval in AI
In the intricate tapestry of language AI, Ollama stands out as a crucial thread, particularly in the context of Retrieval-Augmented Generation (RAG). This section will delve into the essence of Ollama, illuminating its role and significance in the construction of advanced AI systems.
What is Ollama?
Ollama: The Retrieval Powerhouse - At its core, Ollama is a state-of-the-art information retrieval system, meticulously designed to augment language by providing them with the capability to access and utilize external knowledge. In the world of AI where information is king, Ollama acts as the key to unlocking vast troves of data, making it an invaluable asset for any RAG.
The Pillars of Ollama
Efficiency and Speed: Ollama is engineered for high-speed data retrieval, a critical feature for real-time applications and responsive AI systems. Its efficiency ensures that the retrieval process doesn't become a bottleneck in the overall performance of the RAG.
Scalability: Ollama shines in its ability to handle large-scale datasets, maintaining its efficacy and speed regardless of the data volume. This scalability makes it an excellent fit for enterprise-level applications and complex AI projects.
Flexibility: Designed with flexibility in mind, Ollama can be seamlessly integrated with various databases and information sources. This adaptability is crucial for building RAG that rely on diverse and dynamic data sources.
Installation and Setup
Simplifying the Setup: Installing Ollama is a breeze. With your Python environment ready and waiting, a simple pip install ollama command is all it takes to add this powerful retrieval system to your toolkit. This ease of installation belies the complexity and sophistication of the capabilities it brings to your projects.
Configuring Ollama for RAG
Tailoring Ollama for Your Needs: Configuration of Ollama is a straightforward process, allowing you to customize its behavior to suit the specific requirements of your RAG. Whether you need to connect to a particular database or tweak retrieval parameters, Ollama offers the flexibility to make these adjustments with minimal hassle.
Ollama in Action: A Practical Example
Seeing Ollama at Work: In the subsequent sections of this tutorial, we will guide you through practical examples of integrating Ollama with your RAG. You'll learn how to harness its retrieval capabilities to feed relevant information into your language , enriching the context and depth of the generated responses.
Why Ollama for RAG?
The Ideal Retrieval Companion: The synergy between Ollama’s retrieval prowess and the generative capabilities of RAG is undeniable. Ollama provides the essential backbone for the 'retrieval' aspect of RAG, ensuring that the generative has access to the necessary information to produce contextually rich and accurate responses.
In essence, Ollama is not just a tool; it's a gateway to enhanced AI capabilities. Its efficiency, scalability, and adaptability make it an indispensable component in the realm of advanced language AI systems. As we progress through this tutorial, the role of Ollama in empowering your RAG will become increasingly evident, showcasing its value as a cornerstone of modern AI development. Let's venture forth, leveraging Ollama's strengths to break new ground in the exciting world of AI and machine learning.
Building the RAG: A Confluence of Innovation and Engineering
As we delve into the construction of the Retrieval-Augmented Generation (RAG) , we're embarking on a journey at the forefront of AI innovation. This section is dedicated to guiding you through the intricacies of building a RAG, leveraging the combined capabilities of Langchain and Ollama, and culminating in a system that exemplifies the pinnacle of modern language AI.
Architectural Overview of RAG
The RAG represents a fusion of two powerful AI paradigms: retrieval and generation. At its heart, the RAG is a sophisticated algorithm that first retrieves relevant information from a vast dataset (courtesy of Ollama) and then uses this information to generate insightful, context-rich responses (powered by Langchain). This dual-process approach enables the RAG to produce outputs that are not only linguistically coherent but also deeply informed and factually accurate.
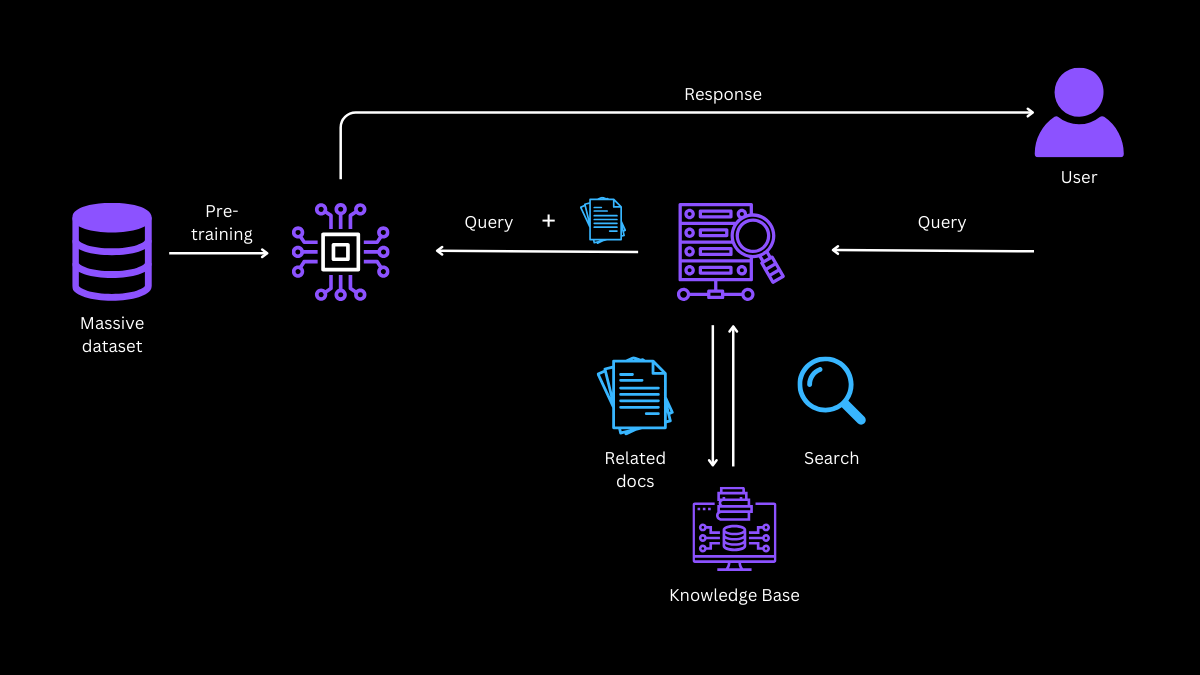
Integrating Langchain with Ollama
In the quest to build more sophisticated and context-aware AI language , the integration of Langchain and Ollama stands out as a beacon of innovation. This segment of our tutorial delves into the practical aspects of this integration, providing a source code example to demonstrate how the seamless synergy between these two powerful tools can revolutionize language processing capabilities.
The Convergence of Retrieval and Generation
The essence of our RAG (Retrieval-Augmented Generation) lies in its ability to amalgamate the retrieval prowess of Ollama with the generative finesse of Langchain. Here, we present a streamlined source code example that encapsulates this integration:
Breaking Down the Code
- Initialization: The code begins with setting up Langchain and Ollama. It's essential to replace
YourFavoriteLLMwith an actual language that suits your project needs. - RAG Chain Creation: The core of the integration is the creation of a RAG chain. This chain links the Ollama retriever and the language , ensuring a smooth flow of information between retrieval and generation.
- Response Generation: The
generate_responsefunction illustrates how a query is processed through the RAG , combining the retrieved information and the original query to produce a comprehensive response. - Example Query: We provide an example to showcase the RAG in action, answering a complex question about quantum computing in AI.
Testing the Integration
The integration of Langchain and Ollama to build a Retrieval-Augmented Generation (RAG) is a significant milestone, but the true measure of success lies in its evaluation. Proper testing and evaluation are critical to ensure that the RAG functions as intended, effectively combining retrieval and generation capabilities to deliver accurate and contextually relevant responses. This section focuses on the methodologies and best practices for evaluating the integrated RAG .
1. Unit Testing: Begin by testing Langchain & Ollama individually. This step will ensure that each component is functioning correctly in isolation, performing their respective tasks.
Further, develop test cases that cover a variety of scenarios, including edge cases, to thoroughly evaluate each component. This might involve testing Langchain with different types of input queries and evaluating Ollama’s ability to retrieve relevant information from diverse data sources.
2. End-to-End Testing: Once individual components are validated, the next step is to test them together. This involves running queries through the complete RAG system and observing the interaction between the retrieval and generation processes.
Use a set of predefined queries that encompass a wide range of topics and complexities. This helps in assessing how well it retrieves relevant information and how effectively it uses this information to generate responses.
3. Evaluating Performance and Accuracy: Evaluate the quality of the responses generated by the RAG. This includes assessing their relevance, coherence, factual accuracy, and linguistic quality. Human evaluators or automated scoring systems can be used for this purpose. Assess the effectiveness of the retrieval component. Analyze if Ollama is fetching pertinent and comprehensive information that significantly contributes to the quality of the generated responses.
4. Fine-Tuning and Optimization: Incorporate a feedback loop where the outputs of the are analyzed for accuracy and relevancy. Use this feedback to fine-tune the , adjusting parameters and settings for better performance.
Employ various metrics like response time, accuracy scores, and relevance metrics to quantitatively evaluate the 's performance. These metrics provide concrete data to guide further optimization.
Enhancing the RAG
Customization: With the basic RAG in place, the next step is to customize it according to the specific needs of your application. This might involve tuning the for specific types of queries or optimizing the retrieval process for efficiency.
Feedback Loop: Implementing a feedback loop can significantly enhance the performance of the RAG. By analyzing the responses generated and the relevance of the retrieved information, you can continuously refine it for better accuracy and relevance.
Deployment and Scaling
Once the RAG is built and thoroughly tested, the final step is to prepare it for deployment. This involves considerations for scalability, especially if it is expected to handle a high volume of queries. The scalable nature of both Langchain and Ollama comes into play here, ensuring that the RAG remains robust and efficient even under heavy loads.
In summary, building a RAG is a complex yet rewarding endeavor that combines cutting-edge AI technologies. Through the integration of Langchain and Ollama, we can create a system that not only understands and generates natural language but also does so with an unprecedented level of contextual awareness and factual accuracy. As we proceed with this tutorial, each step will bring us closer to realizing the full potential of RAG, opening new horizons in the field of language AI.
Running RAG Application Locally: Bringing Your AI to Life
The final, exhilarating stage in our journey of building a Retrieval-Augmented Generation (RAG) is to bring it to life by running it locally. This phase marks the transition from theoretical development to practical application, allowing you to witness the fruition of your hard work firsthand. Let’s navigate through the process of starting your RAG application locally, ensuring a smooth and successful deployment.
Starting the Streamlit Server: Your Window to the RAG
Initiating the Interface: With Streamlit, launching your application is as straightforward as it is exciting. Streamlit's design philosophy centers around ease of use and rapid deployment, making it an ideal choice for showcasing your RAG. To start the server, navigate to the directory containing your Streamlit script and run the command streamlit run your_script.py. This command activates the Streamlit server and serves your application.
Local Hosting: Upon running the command, Streamlit typically hosts your application on a local server, usually accessible via a web browser at localhost:8501. This local hosting allows you to interact with your RAG in a web interface, providing a tangible and user-friendly way to explore its capabilities.
Interacting with the RAG: A User-Centric Approach
User Interface Experience: The Streamlit application offers an intuitive and interactive interface for users to interact with the RAG. You can input queries, adjust parameters, and see the 's responses in real-time. This interactive experience is crucial for understanding the 's capabilities and limitations.
Real-Time Feedback: One of the key advantages of running the application locally is the ability to get real-time feedback. As you input different queries and tweak settings, the responds instantaneously, allowing for a dynamic exploration of its functionalities.
Conclusion: A Milestone in Your AI Journey
Running your RAG application locally is not just a technical achievement; it’s a significant milestone in your journey as an AI developer. It represents the culmination of your efforts in mastering complex AI concepts and tools, and the beginning of a new phase where you can refine, share, and potentially scale.
In conclusion, this phase of the tutorial brings together all the components of your RAG into a tangible, interactive application. By running locally, you gain invaluable insights into its practical functioning, allowing you to appreciate the nuances of AI-driven language processing. This experience is not just about observing the output; it’s about engaging with it, learning from it, and envisioning its potential applications in the real world.




No Hype. Just Systems That Deliver Real Outcomes at Scale.


A1004, Amar Business Zone, Baner, Pune, Maharashtra – 411045





